Écrit par Neil Deakin
,
mise à jour par les contributeurs à MDC
.
Traduit par Laurent Jouanneau (12/08/2004), mise à jour par Alain B. (04/04/2007) .
Page originale :
http://developer.mozilla.org/en/docs/XUL_Tutorial/Templates
Attention : Ce tutoriel est ancien et n'est pas mis à jour. Bien que beaucoup d'informations soient encore valables pour les dernières versions de gecko, beaucoup sont aussi obsolètes. Il est préférable d'aller consulter cette page sur la version française de ce tutoriel sur developer.mozilla.org.
Dans cette section, nous allons voir comment peupler des éléments avec des données.
XUL apporte une méthode permettant de créer des éléments à partir de données fournies par RDF, que ce soit à partir d'un fichier RDF ou à partir d'une source de données interne. Plusieurs sources de données sont déjà fournies avec Mozilla comme les marque-pages, l'historique et les messages mails. Plus de détails seront donnés dans la prochaine section.
Habituellement, les éléments tels que les treeitem et
menuitem
seront peuplés avec des données. Cependant, vous
pouvez utiliser d'autres éléments si vous le voulez, bien qu'ils soient utilisés pour des
cas spécifiques. Néanmoins nous commencerons avec ces autres éléments parce que les arbres
et menus nécessitent plus de code.
Pour permettre la création d'éléments basés sur des données RDF, vous avez besoin de fournir un gabarit simple (Ndt : template) qui sera dupliqué pour chaque élément devant être créé. En gros, vous fournissez juste le premier élément et les suivants seront construits sur le même modèle.
Le gabarit est créé en utilisant l'élément
template. À
l'intérieur de celui-ci, vous pouvez placer les éléments que vous voulez utiliser pour chaque
élément construit. L'élément template
doit être placé à l'intérieur
du conteneur qui contiendra les éléments construits. Par exemple, si vous utilisez un
arbre tree, vous
devez placer l'élément template
à l'intérieur de l'élément tree.
C'est mieux d'expliquer avec un exemple. Prenons un exemple simple où nous voulons créer un bouton pour chaque marque-page principal. Mozilla fournit une source de données pour les marque-pages, pouvant être ainsi utilisée pour récupérer les données. Cet exemple ne récupérera que les marque-pages principaux (ou les dossiers des marque-pages) car nous allons créer des boutons. Pour les marque-pages fils, nous devrions utiliser un élément qui affiche une hiérarchie tel qu'un arbre ou un menu.
Cet exemple et tous les autres qui font référence à des sources de données RDF interne, et ils ne fonctionneront que si vous les chargez à partir d'une url chrome. Pour des raisons de sécurité, Mozilla ne permet pas d'y accéder à partir de fichiers extérieurs.
Pour voir cet exemple, vous devrez créer un paquet chrome contenant le fichier à charger (vous pouvez le faire facilement, consultez les fichiers manifest). Vous pouvez alors entrer l'URL chrome dans le champ de saisie des URLs du navigateur.
Exemple 9.2.1 : Source
<vbox datasources="rdf:bookmarks" ref="NC:BookmarksRoot" flex="1">
<template>
<button uri="rdf:*" label="rdf:http://home.netscape.com/NC-rdf#Name"/>
</template>
</vbox>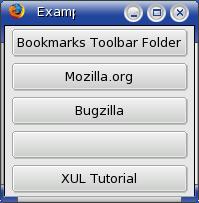 Ici une boîte verticale a été créée contenant une colonne de boutons, un pour chaque marque-page
principal. Vous pouvez voir que le
Ici une boîte verticale a été créée contenant une colonne de boutons, un pour chaque marque-page
principal. Vous pouvez voir que le template ne contient qu'un seul
button. Cet
unique bouton est utilisé comme modèle pour tout les autres boutons qu'il sera nécessaire de créer.
Vous pouvez voir sur l'image qu'un ensemble de boutons a été créé, un pour chaque marque-page.
Essayez d'ajouter un marque-page dans le navigateur pendant que vous avez cet exemple ouvert dans une fenêtre. Vous noterez que les boutons seront mis à jour instantanément (Vous devez donner le focus à la fenêtre pour voir le changement).
Le gabarit lui-même est placé à l'intérieur d'une boîte verticale. La boîte a deux
attributs qui lui permet d'être utilisée pour les gabarits, indiquant d'où les données
proviennent. Le premier attribut de la boîte est datasources.
Il est utilisé pour déclarer la source de données RDF qui fournira les données pour créer les
éléments. Dans le cas présent, rdf:bookmarks est indiqué. Vous devinez probablement
qu'il signifie qu'il faut utiliser la source de données des marque-pages. Cette source de données
est fournie par Mozilla. Pour utiliser votre propre source de données, spécifiez l'URL d'un
fichier RDF dans l'attribut datasources, comme le montre
l'exemple suivant :
<box datasources="chrome://zoo/content/animals.rdf"
ref="http://www.some-fictitious-zoo.com/all-animals">Vous pouvez spécifier plusieurs sources de données à la fois, en les séparant avec un espace dans la valeur de l'attribut. Ainsi, l'affichage de données provenant de multiples sources est possible.
L'attribut ref indique l'endroit dans la source de données à partir
duquel vous voulez récupérer les données. Dans le cas des marque-pages, la valeur NC:BookmarksRoot
est utilisée
pour indiquer la racine de la hiérarchie des marque-pages. Les autres valeurs que vous pouvez indiquer
dépendront de la source de données que vous utiliserez. Si vous utilisez votre propre fichier RDF,
la valeur correspondra à la valeur d'un attribut about d'un élément
RDF Bag, Seq ou Alt.
En ajoutant ces deux attributs à la boîte du dessus, vous permettez la génération d'éléments
en utilisant le gabarit. Cependant, les éléments à l'intérieur du gabarit nécessite une déclaration
différente. Vous noterez dans l'exemple du dessus que le bouton a un attribut
uri et a une valeur inhabituelle pour l'attribut
label.
Un attribut à l'intérieur d'un gabarit qui commence par rdf: indique que la valeur
doit être prise à partir de la source de données. Dans l'exemple plus haut, c'est le cas de l'attribut
label. Le reste de la valeur réfère au nom de la propriété dans la source
de données. Elle est construite en prenant l'URL de l'espace de nom utilisé par la source de données et
en y ajoutant le nom de la propriété. Ici, nous utilisons seulement le nom du marque-page mais d'autres
champs sont disponibles.
L'attribut label des boutons est renseigné avec cet URI spécial parce
que nous voulons que les libellés des boutons aient le nom des marque-pages. Nous pouvons mettre cet URI
sur n'importe quel attribut de l'élément button,
ou n'importe quel élément.
Les valeurs de ces attributs sont remplacées par les données fournies par la source de données qui,
ici, sont les marque-pages. Pour finir, les libellés des boutons sont définis par les noms des marque-pages.
L'exemple du dessous montre comment nous pourrions assigner d'autres attributs d'un bouton à partir de la source de données. Bien sûr, cela implique que la source de données fournisse les ressources appropriées. Si une ressource particulière est inexistante, la valeur de l'attribut sera une chaîne vide.
<button class="rdf:http://www.example.com/rdf#class"
uri="rdf:*"
label="rdf:http://www.example.com/rdf#name"
crop="rdf:http://www.example.com/rdf#crop"/>Comme vous pouvez le voir, vous pouvez générer dynamiquement une liste d'éléments avec les attributs fournis par une source de données séparée.
L'attribut uri est utilisé pour spécifier l'élément où la
génération du contenu commencera. Le contenu extérieur ne sera généré qu'une seule fois, tandis
que le contenu intérieur sera généré pour chaque ressource. Nous en verrons plus à ce propos quand
nous créerons des gabarits pour les arbres.
En ajoutant ces fonctionnalités au conteneur dans lequel est le gabarit, qui dans ce cas est une boîte, et aux éléments à l'intérieur du gabarit, nous pouvons générer de multiples listes de contenu à partir de données externes. Nous pouvons bien sûr mettre plus d'un élément à l'intérieur du gabarit, et ajouter une référence RDF spéciale dans les attributs sur n'importe quel élément. L'exemple suivant le montre :
Exemple 9.2.2 : Source
<vbox datasources="rdf:bookmarks" ref="NC:BookmarksRoot" flex="1">
<template>
<vbox uri="rdf:*">
<button label="rdf:http://home.netscape.com/NC-rdf#Name"/>
<label value="rdf:http://home.netscape.com/NC-rdf#URL"/>
</vbox>
</template>
</vbox>Cet exemple crée une boîte verticale avec un bouton et un libellé pour chaque marque-page. Le bouton contiendra le nom du marque-page et le libellé contiendra l'URL.
Les nouveaux éléments qui sont créés ne sont fonctionnellement pas différents de ceux que vous mettez
directement dans le fichier XUL. L'attribut id est ajouté
à tous les éléments créés au travers du gabarit, et il est assigné à la valeur qui identifie
la ressource. Vous pouvez l'utiliser pour identifier la ressource.
Vous pouvez aussi spécifier de multiples ressources dans le même attribut en les séparant avec un espace, comme dans l'exemple qui suit (en savoir plus sur la syntaxe des ressources).
Exemple 9.2.3 : Source
<vbox datasources="rdf:bookmarks" ref="NC:BookmarksRoot"
flex="1">
<template>
<label uri="rdf:*" value="rdf:http://home.netscape.com/NC-rdf#Name rdf:http://home.netscape.com/NC-rdf#URL"/>
</template>
</vbox>Quand un élément a un attribut datasources, cela indique que l'élément
est susceptible d'être généré à partir d'un gabarit. Notez que ce n'est pas la balise
template
qui détermine si le contenu sera généré, mais bien l'attribut
datasources. Quand cet attribut est présent, un objet que l'on appelle
un constructeur est ajouté à l'élément. C'est cet objet qui est responsable de la génération du
contenu à partir du gabarit. En javascript, vous pouvez accéder à l'objet constructeur par la
propriété builder, bien qu'habituellement vous en aurez seulement besoin pour
régénérer le contenu dans les situations où il ne le fait pas automatiquement.
Il y a deux différents types de constructeur. Le premier est un constructeur de contenu
utilisé dans la plupart des situations, et l'autre est un constructeur d'arbres utilisé
uniquement avec les éléments tree.
Le constructeur de contenu prend le contenu situé à l'intérieur de l'élément
template
et le duplique pour chaque ligne. Par exemple,
si l'utilisateur a dix marque-pages dans l'exemple du dessus, dix éléments
label
seront créés et ajoutés en tant que fils à l'élément
vbox. Si vous
utilisez les fonctions DOM pour traverser l'arbre, vous trouverez ces éléments à ces emplacements et pourrez
récupérer leurs propriétés. Ces éléments sont affichés, mais pas l'élément
template,
bien qu'il existe encore dans l'arbre du document. De plus, l'attribut
id de chaque libellé sera initialisé avec la ressource RDF de la ligne
correspondante.
Le constructeur de contenu démarre toujours à partir de l'élément qui à l'attribut
uri="rdf:*". Si l'attribut uri
est placé à l'intérieur d'autres éléments, ces derniers ne seront créés qu'une seule fois. Dans l'exemple
ci-dessous, un hbox
sera créé et rempli avec un label
pour chaque item.
<template>
<hbox>
<label uri="rdf:*" value="rdf:http://home.netscape.com/NC-rdf#Name"/>
</hbox>
</template>S'il y a du contenu à l'intérieur de l'élément qui a l'attribut datasources
mais en dehors de l'élément template,
ce contenu apparaîtra également. Ce faisant, vous pouvez mélanger du contenu statique et dynamique dans un gabarit.
Le constructeur d'arbres, d'autre part, ne génère pas d'éléments DOM pour chaque ligne. À la place, il récupère les données directement à partir de la source de données RDF quand il en a besoin. Comme les arbres ont souvent besoins d'afficher des centaines de lignes de données, c'est plus efficace comme ceci. Créer un élément pour chaque cellule serait trop coûteux. Cependant, en contre partie, ces arbres ne peuvent afficher que du texte (NdT : ainsi que des images et des cases à cocher), et comme aucun élément n'est créé, vous ne pouvez pas utiliser les propriétés CSS de manière habituelle pour décorer les cellules de l'arbre.
Le constructeur d'arbres est utilisé seulement pour les arbres. Les autres éléments n'utilisent que
le constructeur de contenu. Ceci n'est pas un problème étant donné que les autres éléments comme les
menus n'ont généralement pas besoin d'afficher beaucoup d'items. Il est possible également
d'utiliser le constructeur de contenu pour les arbres, ainsi un élément
treeitem
et d'autres seront crées pour chaque ligne.
Dans l'image du précédent exemple, vous avez pu noter que le troisième bouton est simplement un bouton avec des tirets comme libellé. C'est un séparateur dans la liste des marque-pages. Au cas où nous l'utiliserions, la source de données RDF des marque-pages stocke les séparateurs comme si ils étaient des marque-pages normaux. Ce que nous voulons faire est d'ajouter un petit espace à la place d'un bouton pour les ressources "séparateur". Ce qui signifie que nous voulons avoir deux différents types de contenu à créer, un type pour les marque-pages normaux, et un autre type pour les séparateurs.
Nous pouvons le faire en utilisant un élément
rule. Nous définissons une
règle pour chaque variation des éléments que nous avons à créer. Dans notre cas, nous aurons besoin d'une règle
pour les marque-pages, et une règle pour les séparateurs. Les attributs placés sur l'élément
rule déterminent quelle
règle s'applique sur quelle ressource RDF.
Pour savoir quelle règle s'applique sur les données, chaque élément
rule est analysé
en séquence pour une vérification de concordance. De fait, l'ordre dans lequel
vous définissez les règles est important. Les règles du début ont priorité sur les règles
suivantes.
L'exemple suivant modifie l'exemple précédant avec deux règles.
Exemple 9.2.4 : Source
<window
id="example-window"
title="Liste des marque-pages"
xmlns:html="http://www.w3.org/1999/xhtml"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns="http://www.mozilla.org/keymaster/gatekeeper/there.is.only.xul">
<vbox datasources="rdf:bookmarks" ref="NC:BookmarksRoot" flex="1">
<template>
<rule rdf:type="http://home.netscape.com/NC-rdf#BookmarkSeparator">
<spacer uri="rdf:*" height="16"/>
</rule>
<rule>
<button uri="rdf:*" label="rdf:http://home.netscape.com/NC-rdf#Name"/>
</rule>
</template>
</vbox>
</window>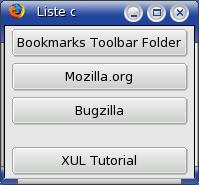 En utilisant deux règles, nous permettont au contenu du gabarit d'être généré sélectivement. Dans le premier
En utilisant deux règles, nous permettont au contenu du gabarit d'être généré sélectivement. Dans le premier
rule,
les séparateurs de marque-pages sont sélectionnés, comme
nous pouvons le voir par l'attribut rdf:type. Le second
rule
n'ayant aucun attribut, il sélectionne tout le reste.
Tous les attributs placés dans l'élément rule,
sont utilisés comme critère de sélection. Dans notre cas, la source de données des marque-pages
fournit une propriété rdf:type pour distinguer les séparateurs.
Cet attribut contient une valeur spéciale pour les séparateurs dans la source de données
RDF. C'est ainsi qu'on peut les distinguer des marque-pages. Vous pouvez utiliser
une technique similaire pour n'importe quel attribut que l'on peut mettre sur un élément RDF
Description.
La valeur spéciale d'URL donnée dans l'exemple du dessus pour la première règle, est utilisée
pour les séparateurs. Elle signifie que les séparateurs s'appliqueront à la première règle
en générant un élément spacer
d'une hauteur de 16 pixels. Les éléments
qui ne sont pas des séparateurs ne correspondront pas à la première règle, et atterriront
dans la deuxième règle. Celle-ci n'a aucun attribut. Elle correspond à n'importe quelle
donnée. Ce qui bien sûr, est ce que nous voulons pour le reste des données.
Vous avez dû noter que, parce que nous voulons un attribut provenant de l'espace de nommage du RDF
(rdf:type), nous avions besoin d'ajouter la déclaration de cet espace de nommage dans la balise
window.
Si nous n'avions pas fait cela, l'attribut serait attribué
à l'espace de nommage XUL. Parce qu'il n'existe pas dans cet espace, la règle ne s'appliquerait pas.
Si nous utilisons des attributs provenant de notre propre espace de nommage, vous devez
ajouter la déclaration de votre espace de nommage pour qu'ils soient reconnus.
Vous devez deviner ce qui arriverait si la seconde règle était enlevée. Le résultat serait alors
un simple spacer,
sans aucun marque-page puisqu'ils ne correspondent à aucune règle.
Dit plus simplement, une règle correspond si tous les attributs placés dans l'élément
rule
correspondent aux attributs de la ressource RDF. Dans le cas d'un
fichier RDF, les ressources seraient les éléments Description.
Il y a cependant quelques petites exceptions. Vous ne pouvez pas faire la correspondance
avec les attributs id, rdf:property ou
rdf:instanceOf. Mais puisque vous utiliserez vos propres
attributs dans votre propre espace de nommage, ces exceptions n'auront probablement pas d'importance de toute façon.
Notez qu'un gabarit sans règle, comme dans le premier exemple, est équivalent fonctionnellement
à un gabarit qui possède un seul rule
sans attribut.
Nous allons voir maintenant l'utilisation des gabarits avec les arbres.