RDF, c'est un moyen d'exprimer des relations. Ces relations sont décrites sous forme de graphe. Chaque nœud du graphe est une ressource ou une valeur. Et chaque nœud est relié à un autre par un arc "nommé".
Exemple :
[[urn:users:456]] -> http://xulfr.org/users#name -> laurentCe qui donne, graphiquement :
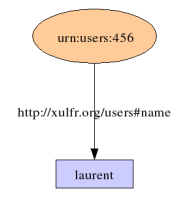
Nous avons ici deux noeuds, "urn:users:456" et "laurent", reliés par un arc nommé "http://xulfr.org/users#name".
En d'autres termes :
Sachant que la cible peut être un littéral comme ici, ou une autre ressource. Toute ressource possède un identifiant sous forme d'uri (url ou urn). Si une ressource ne possède pas explicitement un identifiant, le logiciel qui lira le RDF en attribuera un implicitement. Les prédicats sont également identifiés par une url.
Légende dans les schémas qui suivent :
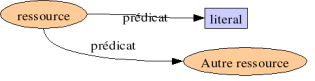
Attention : les urls que l'on utilise dans un fichier RDF ne sont pas forcément des urls web existantes. C'est juste un moyen d'avoir un identifiant unique pour chaque ressource et prédicat.
En fait, on peut faire une analogie entre les bases de données relationnelles SQL, et RDF. On peut décrire le contenu d'une base de donnée sous forme RDF (bien qu'avec RDF, on puisse aller plus loin que ce que permet un SGBD en terme de relations ).
Voyons par exemple comme exprimer le contenu d'une table SQL "news". Imaginons que cette table contienne les champs "id_news", "titre", "texte", "date". En RDF, les noms des champs vont être les prédicats. Leurs valeurs de ces champs seront les valeurs associées à ces prédicats. Et chaque enregistrement constituera alors une ressource.
Voici trois news :
| id_news | titre | texte | date |
| 1 | foo | blablafoo | 01/01/2006 |
| 2 | bar | blablabar | 01/01/2006 |
| 3 | baz | blablabaz | 02/01/2006 |
Comme toute table sql, nous avons à faire à une liste de données. Nous allons donc créer une ressource que l'on appellera "urn:listenews" (on pourrait aussi utiliser une url, par exemple http://xulfr.org/ressources/listenews). Cette ressource contiendra une liste d'autres ressources qui elles mêmes contiendront les informations de chaque news.
Nous utilisons la balise RDF <Bag> pour exprimer le fait que l'on a à faire à une liste non ordonnée. Pour indiquer une liste ordonnée, on aurait utilisé <Seq>. L'attribut RDF:about permet d'indiquer l'url de la ressource.
Voici donc cette première ressource :
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
[[xmlns:RDF="!http://www.w3.org/1999/02/22-rdf-syntax-ns#"]]> <Bag RDF:about="[[urn:listenews"]]> </Bag>
</RDF>On va maintenant dire que cette ressource "urn:listenews", contient les ressources correspondantes à chaque news. On donnera alors à chacune de ces ressources une url, dans laquelle on utilisera l'id de la news : "urn:news:id_de_la_news". Cela permet d'avoir des urls uniques et cohérentes pour chaque news.
On liste le contenu d'un <Bag> au moyen de la balise <li>. En fait, chaque <li> est un prédicat (de nom li). Et la valeur de ces prédicats sera une url de ressource (en l'occurence, l'url d'une ressource de news), que l'on indique au moyen de l'attribut RDF:resource.
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
[[xmlns:RDF="!http://www.w3.org/1999/02/22-rdf-syntax-ns#"]]> <Bag RDF:about="[[urn:listenews"]]>
<li RDF:resource="urn:news:1"/>
<li RDF:resource="urn:news:2"/>
<li RDF:resource="urn:news:3"/>
</Bag>
</RDF>On a ainsi créé le graph suivant :
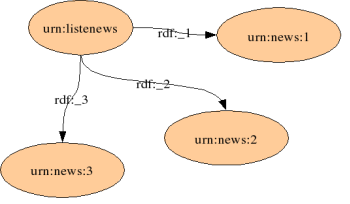
Maintenant, il faut décrire ce que contiennent les ressources urn:!news:*. Pour cela on a la balise <Description> en RDF. On va en créer une pour chaque ressource news. On utilise encore l'attribut RDF:about pour indiquer à quel ressource la description est rattachée.
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
[[xmlns:RDF="!http://www.w3.org/1999/02/22-rdf-syntax-ns#"]]> <Bag RDF:about="[[urn:listenews"]]>
<li RDF:resource="urn:news:1"/>
<li RDF:resource="urn:news:2"/>
<li RDF:resource="urn:news:3"/>
</Bag> <Description RDF:about="urn:news:1"/>
<Description RDF:about="urn:news:2"/>
<Description RDF:about="urn:news:3"/>
</RDF>Malgré l'ajout de ces balises, notre graphe n'a toujours pas changé. On va maintenant remplir les descriptions. On va en fait indiquer les prédicats correspondant à chaque champs des enregistrements. On va utiliser le namespace http:xufr.org/ns/news#// comme racine de leur url, que l'on déclare à la racine du document :
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
[[xmlns:RDF="!http://www.w3.org/1999/02/22-rdf-syntax-ns#]]"
[[xmlns:news="!http://xufr.org/ns/news#"]]>Voici les descriptions complètes :
<Description RDF:about="urn:news:1" news:id_news="1" news:titre="foo" news:texte="blablafoo" news:date="01/01/2006" />
<Description RDF:about="urn:news:2" news:id_news="2" news:titre="bar" news:texte="blablabar" news:date="01/01/2006" />
<Description RDF:about="urn:news:3" news:id_news="3" news:titre="baz" news:texte="blablabaz" news:date="02/01/2006" />Ici on a utilisé des attributs, mais on peut aussi utiliser des éléments, cela revient strictement au même. Par exemple :
<Description RDF:about="urn:news:1">
<news:id_news>1</!news:id_news>
<news:titre>foo</!news:titre>
<news:texte>blablafoo</!news:texte>
<news:date>01/01/2006</!news:date>
</Description>Notre contenu rdf complet est le suivant
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
[[xmlns:RDF="!http://www.w3.org/1999/02/22-rdf-syntax-ns#]]"
[[xmlns:news="!http://xufr.org/ns/news#"]]> <Bag RDF:about="[[urn:listenews"]]>
<li RDF:resource="urn:news:1"/>
<li RDF:resource="urn:news:2"/>
<li RDF:resource="urn:news:3"/>
</Bag> <Description RDF:about="urn:news:1">
<news:id_news>1</!news:id_news>
<news:titre>foo</!news:titre>
<news:texte>blablafoo</!news:texte>
<news:date>01/01/2006</!news:date>
</Description>
<Description RDF:about="urn:news:2" news:id="2" news:titre="bar" news:texte="blablabar" news:date="01/01/2006" />
<Description RDF:about="urn:news:3" news:id="3" news:titre="baz" news:texte="blablabaz" news:date="02/01/2006" />
</RDF>Ce qui correspond à ce graphe plus complet maintenant :
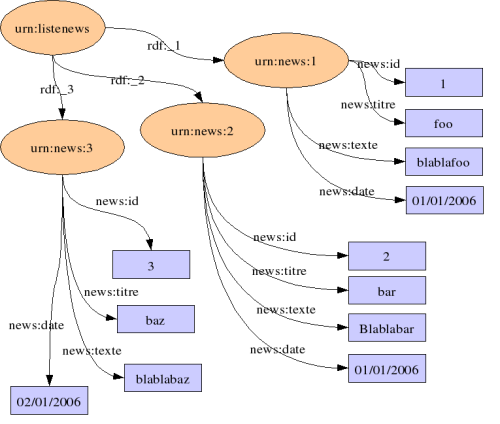
Nous voulons maintenant classer les news dans des catégories. En SQL, nous aurions fait une table catégories, contenant les champs id_cat, et libelle.
| id_cat | libelle |
| 1 | "technologie" |
| 2 | "Mozilla" |
Et les enregistrements de la table news aurait un id_cat également (clé étrangère). Les descriptions de nos news deviendraient alors :
<Description RDF:about="urn:news:1">
<news:id_news>1</!news:id_news>
<news:id_cat>1</!news:id_cat>
<news:titre>foo</!news:titre>
<news:texte>blablafoo</!news:texte>
<news:date>01/01/2006</!news:date>
</Description>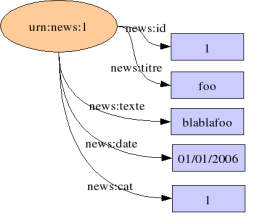
Le problème ici, c'est que l'on a que l'id de la catégorie. Comment inclure alors le reste des informations contenant les catégories ? On pourrait faire ceci :
<Description RDF:about="urn:news:1">
<news:id_news>1</!news:id_news>
<news:id_cat>
<Description>
<[[cat:id_cat>1</cat:id_cat]]>
<[[cat:libelle>technologie</cat:libelle]]>
</Description>
</news:id_cat>
<news:titre>foo</!news:titre>
<news:texte>blablafoo</!news:texte>
<news:date>01/01/2006</!news:date>
</Description>Sans oublier dans la racine du document de déclarer le namespace cat :
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
[[xmlns:RDF="!http://www.w3.org/1999/02/22-rdf-syntax-ns#]]"
[[xmlns:news="!http://xufr.org/ns/news#]]"
[[xmlns:cat="!http://xufr.org/ns/categories#]]"
>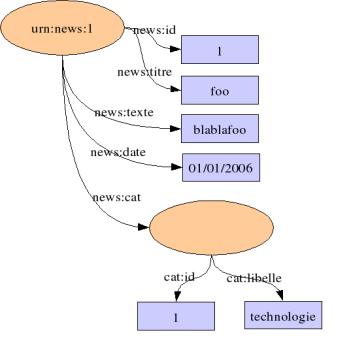
On a ainsi modifié le prédicat news:id_cat : sa valeur n'est plus un littéral, mais une nouvelle ressource, que l'on a décrite grâce à la balise Description. Attention, faire ceci n'a aucun sens en RDF :
<news:id_cat>
<[[cat:id_cat>1</cat:id_cat]]>
<[[cat:libelle>technologie</cat:libelle]]>
</news:id_cat>On a décrit des ressources catégories pour chaque news, mais on a toutefois un autre problème : si plusieurs news sont dans les mêmes catégories, on va avoir des informations redondantes (ici le libelle). Notre graphe ne va pas être "optimisé". Utilisons au mieux alors le RDF, et faisons une sorte de jointure comme on fait en SQL :
1) on va créer une ressource pour chaque catégorie, que l'on va décrire dans une balise <Description> comme on l'a fait précédemment, mais cette fois-ci, on va les déclarer en dehors des ressources news et on va les référencer avec une url de type "urn:categorie:id_de_la_categorie" :
<Description RDF:about="[[urn:categorie:1]]" [[cat:id_cat="1]]" [[cat:libelle="technologie]]" />
<Description RDF:about="[[urn:categorie:2]]" [[cat:id_cat="2]]" [[cat:libelle="Mozilla]]" />2) Et dans le prédicat "news:id_cat", on lui indique que sa valeur est l'une de ces ressources, grâce à l'attribut RDF:resource :
<Description RDF:about="urn:news:1">
<news:id_news>1</!news:id_news>
<news:id_cat RDF:resource="[[urn:categorie:1]]" />
<news:titre>foo</!news:titre>
<news:texte>blablafoo</!news:texte>
<news:date>01/01/2006</!news:date>
</Description>Cela donne :
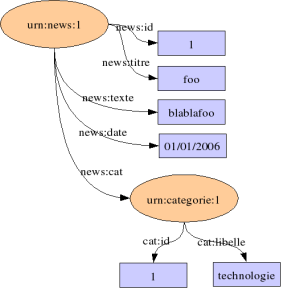
Vous remarquerez que le graphe n'a pas beaucoup changé, concernant la ressource urn:news:1.
Le fichier rdf entier :
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
[[xmlns:RDF="!http://www.w3.org/1999/02/22-rdf-syntax-ns#]]"
[[xmlns:news="!http://xufr.org/ns/news#]]"
[[xmlns:cat="!http://xufr.org/ns/categories#]]"
> <Bag RDF:about="[[urn:listenews"]]>
<li RDF:resource="urn:news:1"/>
<li RDF:resource="urn:news:2"/>
<li RDF:resource="urn:news:3"/>
</Bag> <Description RDF:about="urn:news:1">
<news:id_news>1</!news:id_news>
<news:id_cat RDF:resource="[[urn:categorie:1]]" />
<news:titre>foo</!news:titre>
<news:texte>blablafoo</!news:texte>
<news:date>01/01/2006</!news:date>
</Description>
<Description RDF:about="urn:news:2" news:id="2" news:titre="bar" news:texte="blablabar" news:date="01/01/2006">
<news:id_cat RDF:resource="[[urn:categorie:1]]" />
</Description>
<Description RDF:about="urn:news:3" news:id="3" news:titre="baz" news:texte="blablabaz" news:date="02/01/2006">
<news:id_cat RDF:resource="[[urn:categorie:2]]" />
</Description> <Description RDF:about="[[urn:categorie:1]]" [[cat:id_cat="1]]" [[cat:libelle="technologie]]" />
<Description RDF:about="[[urn:categorie:2]]" [[cat:id_cat="2]]" [[cat:libelle="Mozilla]]" />
</RDF>Pour avoir une liste de toutes les ressources catégories, il suffit de créer une nouvelle liste, comme on l'a fait pour avoir la liste des news.
<Bag RDF:about="[[urn:listecategories"]]>
<li RDF:resource="[[urn:categorie:1"/]]>
<li RDF:resource="[[urn:categorie:2"/]]>
<li RDF:resource="[[urn:categorie:3"/]]>
</Bag>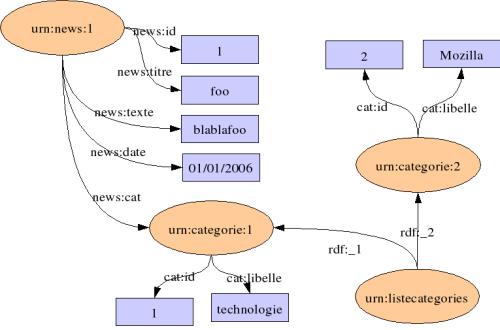
On remarque donc qu'un fichier RDF "basique", ce n'est rien d'autre que :
Copyright © 2003-2013 association xulfr, 2013-2016 Laurent Jouanneau - Informations légales.
Mozilla® est une marque déposée de la fondation Mozilla.
Mozilla.org™, Firefox™, Thunderbird™, Mozilla Suite™ et XUL™
sont des marques de la fondation Mozilla.