De nombreux langages offrent des solutions simples pour lire un fichier sur votre disque dur. La technique utilisée par Mozilla nécessite l'emploi d'interfaces XPCOM pour accéder à vos fichiers, ainsi que des privilèges accrus.
Les privilèges dont il est question ici concernent principalement la capacité de lire et d'écrire des fichiers locaux, c'est à dire placé sur votre propre ordinateur, et non pas sur un serveur distant (en d'autres termes : sur le net)
Il n'existe pas de fonction prédéfinie en javascript permettant de réaliser une telle opération, et il existe plusieurs méthodes de lecture d'un fichier. C'est pour cette raison que le script peut paraître compliqué (mais il est expliqué ici dans le détail).
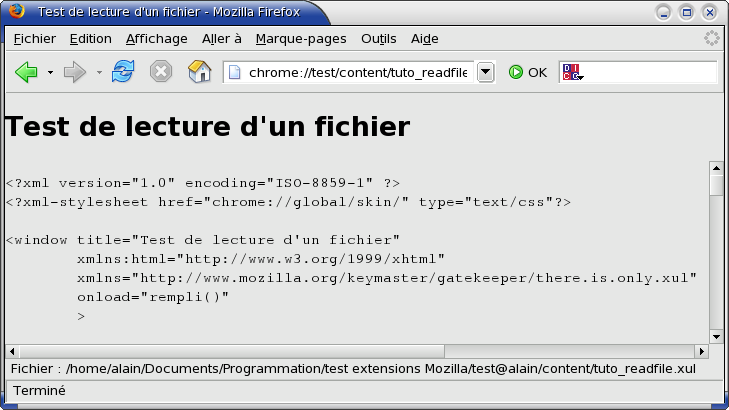
(voir aussi :le même code, sans commentaires)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!--
En-tête de tout fichier XML. Il ne doit rien y avoir avant ce ligne.
encoding="…" définit le type d'encodage. C'est à dire, en quelque sorte et
pour faire simple, la langue informatique dans laquelle le fichier va être
écrit
On aurait pu trouver "utf-8" par exemple, à la place de "ISO-8859-1", qui
est une autre façon d'écrire les caractères de votre code.
--> <?xml-stylesheet href="[[chrome://global/skin/]]" type="text/css"?>
<!--
Cette ligne demande le chargement d'une feuille de styles (stylesheet). C'est
la feuille de style "global" du chrome qui définit la façon dont vont appa-
raître la plupart des éléments graphiques : bouton, menus, etc.
type="text/css" : précise que ledit fichier style est écrit en "text", et
suivant le langage "css" (cascading styles sheet).
--> <window title="Test de lecture d'un fichier"
[[xmlns:html="!http://www.w3.org/1999/xhtml]]"
xmlns="http://www.mozilla.org/keymaster/gatekeeper/there.is.only.xul"
onload="rempli()"
>
<!--
• Avec ce <window …>, on "marque" le début de la définition de la fenêtre
(window = fenêtre en anglais)
• Cette fenêtre aura pour titre "Test de lecture d'un fichier"
• Les deux lignes suivante détermine les "espaces de nom" (namespace).
Remarquez le début : xmlns = "XML" + n (name) + s (space)
Pour faire simple, avec ces deux lignes, c'est comme si on embauchait deux
traducteurs qui allaient pouvoir interpréter les balises qu'on sera amené
à utiliser dans la suite de ce code ''(si un meilleur que moi pouvait indiquer l'utilisation du point d'exclamation,
ce serait bien)''
• Enfin, la dernière ligne (onload="rempli()") dit au programme qu'après le
chargement de la page (on-load), il faudra appeler la fonction javascript
"rempli()" qui sera définie plus bas.
--> <script><![CDATA[
/*
La balise <script> indique qu'on va insérer du code javascript (nos fonctions
et autres) ici. Elle sera fermée par un "</script>" que vous pouvez trouver
plus bas. Le "<![CDATA[" ésotique indique simplement au programme qui lira ce fichier
qu'à partir d'ici, il ne faudra pas chercher à "interpréter" en xml ou autre.
C'est comme si on disait : écris le code tel quel, sans rien toucher.
Ça sera valable jusqu'au "]" qu'on trouvera plus bas, avant la balise
"</script>" de fin de script.
*/ function rempli() {
/*
Voilà la fonction qui sera appelé sitôt après le chargement de la page.
*/ var uri = "<mettre ici le chemin vers votre fichier>"; var txt = read(uri);
/*
La fonction "read(…)" qui est appelée ici sera définie plus bas. Ici,
nous disons simplement qu'il faudra l'appelée avec le chemin d'accès
au fichier (uri) et que cette fonction renverra le texte du-dit fichier.
*/ //''Affichage du contenu en échappant les caractères xml''
txt = txt.replace(/&/g, '&');
txt = txt.replace(/</g, '<');
txt = txt.replace(/>/g, '>'); /*
(si ces lignes sont claires pour vous, vous pouvez passer ce bloc) Le code ci-dessus est un peu compliqué en apparence, parce qu'il fait
appel à plusieurs considérations. Essayons de procéder par élimination.
— D'abord, comprendre que "txt.replace(…)" veut simplement dire qu'on doit
remplacer 'quelque chose' par 'autre chose' :
monTexteCorrige =
monTexteNonCorrige.replace('quelque chose', 'autre chose');
— On utilise pour ce faire, ici, une expression régulière. Nous ne pouvons
pas donner ici le détail de ce que c'est. Pour faire simple : si nous
demandons à javascript de remplacer "renard" par "loup", c'est un
remplacement "simple". En revanche, si nous voulons faire plus
compliqué, et dire qu'il faut remplacer tous les mots commençant par
"l" et se terminant par "p" par des "renard", alors nous devons
utiliser les expressions régulières (note : ici, on n'a pas besoin, me
semble-t-il, d'utiliser les expressions régulièrement simplement pour
dire à javascript qu'il doit remplacement TOUTES les occurences qu'il
trouvera dans le texte (c'est ce que veut dire le "g").
Comment tout ceci prend-il forme ? Très simplement : les "/" disent à
la méthode "replace" qu'on va lui donner une expression régulière. Elle
va commencer à "/" et se terminer à… "/". Tout ce qui suivra (le "g" ici)
sera des indications de plus pour le remplacement (ici : remplacer TOUTES
les occurences)
En conclusion, si nous "humanisons" l'expression…
txt = txt.replace(/&/g, "&");
… elle signifie : « prend le texte dans 'txt', remplace toutes les
esperluettes (&) que tu trouveras par des '&', et redonne le
résultat à la variable 'txt'. »
La suite est identique : remplacer tous les '<' par des '<',
remplacer tous les '>' par des '>'. Mais pourquoi diable faire ces remplacements ?… Tout simplement pour
remplacer ces caractères par leur « entité HTML ». Pour faire simple :
Si nous écrivons '<', le programme va croire que nous définissons le
début d'une balise, ou autre chose, et va chercher à l'interpréter.
Nous, nous voulons seulement qu'il écrive un signe « inférieur à ».
Pour l'obliger à le faire, nous remplaçons ces signes ambigus par leur
« entité HTML »
*/ document.getElementById('contenu').innerHTML = txt;
/*
Cette ligne dit à javascript de mettre le text 'txt' dans l'élément
du document qui s'appelle 'contenu' (= qui a pour id 'contenu') :
« Document, prend (get) l'élément (Element) par son id (ByID) qui
est 'contenu', et met entre ses balises HTML (innerHTML) le texte
'txt'. note : bien sûr, plus bas dans cette page, il nous faudra créer cet
élément qui aura pour id 'contenu'.
*/ //''Un peu de cosmétique, affichage du chemin du fichier en bas de la fenêtre''
document.getElementById('nom_fichier').value = "Fichier : " + uri;
/*
De la même façon qu'on a mis dans l'élément 'contenu' le texte, on
demande à javascript de mettre le chemin d'accès de notre fichier
dans un élément qui s'appelle 'nom_fichier' (= qui a pour
id 'nom_fichier')
*/
}
/* Nous avons fini de définir notre première fonction, celle qui est
appelée à la fin du chargement de la page. Il nous faut maintenant définir notre fonction 'read(…)' qui va
lire le fichier spécifié par 'uri' ci-dessus. Dans la fonction
read(), cet 'uri' s'appelera 'filepath'. C'est un texte (string)
qui peut ressembler à "/chemin/vers/mon/beau/fichier/a/lire.txt"
*/Copyright © 2003-2013 association xulfr, 2013-2016 Laurent Jouanneau - Informations légales.
Mozilla® est une marque déposée de la fondation Mozilla.
Mozilla.org™, Firefox™, Thunderbird™, Mozilla Suite™ et XUL™
sont des marques de la fondation Mozilla.