Écrit par Neil Deakin
,
mise à jour par les contributeurs à MDC
.
Traduit par Cyril Delalande et Laurent Jouanneau (15/08/2004), mise à jour par Alain B. (04/04/2007) .
Page originale :
http://developer.mozilla.org/en/docs/XUL_Tutorial/Trees_and_Templates
Attention : Ce tutoriel est ancien et n'est pas mis à jour. Bien que beaucoup d'informations soient encore valables pour les dernières versions de gecko, beaucoup sont aussi obsolètes. Il est préférable d'aller consulter cette page sur la version française de ce tutoriel sur developer.mozilla.org.
Nous allons voir maintenant comment utiliser un gabarit avec un arbre.
Avec un arbre, vous utiliserez souvent un gabarit pour construire son contenu,
pour manipuler un grand volume de données hiérarchisées. L'utilisation d'un gabarit avec un
arbre est très proche au niveau de la syntaxe aux autres éléments. Vous avez besoin d'ajouter
un attribut datasources et ref à
la balise tree,
ce qui spécifie la source des données et le noeud racine à afficher.
De nombreuses règles peuvent être utilisées pour indiquer différents contenus pour
différents types de données.
L'exemple suivant utilise l'historique comme source de données :
<tree datasources="rdf:history" ref="NC:HistoryByDate"
flags="dont-build-content">Comme il est décrit dans la section précédente, l'arbre peut utiliser un constructeur d'arbre
pour la génération du gabarit à la place du constructeur normal de contenu.
Les éléments ne seront pas créés pour chacune des lignes dans l'arbre, afin de le
rendre plus performant. Lorsque l'attribut flags a pour valeur
dont-build-content, comme dans l'exemple ci-dessus, il indique que le constructeur
de l'arbre doit être utilisé. Si l'attribut n'est pas renseigné, le constructeur de
contenu sera utilisé. Vous pouvez voir la différences en utilisant l'inspecteur DOM de
Mozilla sur un arbre avec, puis sans l'attribut.
Si vous utilisez le constructeur normal à la place, notez que le contenu ne sera pas construit avant qu'il soit nécessaire. Avec les arbres hiérarchiques, les enfants ne sont pas générés avant que le n½ud parent ne soit ouvert par l'utilisateur.
Dans le gabarit, il n'y aura qu'une cellule
treecell
pour chaque colonne dans l'arbre. Les cellules devront avoir un attribut label
afin de mettre un libellé à la cellule. Normalement, une propriété RDF se charge de récupérer
le libellé à partir de la source de données.
L'exemple suivant montre un arbre construit à partir d'un gabarit, dans ce cas le système de fichier.
Exemple 9.3.1 : Source
<tree id="my-tree" flex="1"
datasources="rdf:files" ref="file:///" flags="dont-build-content">
<treecols>
<treecol id="Name" label="Nom" primary="true" flex="1"/>
<splitter/>
<treecol id="Date" label="Date" flex="1"/>
</treecols>
<template>
<rule>
<treechildren flex="1">
<treeitem uri="rdf:*">
<treerow>
<treecell label="rdf:http://home.netscape.com/NC-rdf#Name"/>
<treecell label="rdf:http://home.netscape.com/WEB-rdf#LastModifiedDate"/>
</treerow>
</treeitem>
</treechildren>
</rule>
</template>
</tree>Ici, un arbre est créé avec deux colonnes, pour le nom et la date d'un fichier. L'arbre
doit afficher une liste de fichiers situés dans le répertoire racine. Une seule règle est
utilisée, mais vous pouvez en ajouter d'autres si vous en avez besoin. Comme avec les autres
gabarits, l'attribut uri d'un élément indique où commencer pour
générer du contenu. Les deux cellules puisent le nom et la date dans la source et place les
valeurs dans le libellé de la cellule.
Cet exemple montre pourquoi l'attribut uri devient utile.
Notez comment il a été placé dans le treeitem
dans l'exemple, même si ce n'est pas un descendant direct de l'élément
rule.
Nous avons besoin de mettre cet attribut seulement sur les éléments que nous voulons répéter pour
chaque ressource. Comme nous ne voulons pas des éléments
treechildren
multiples, l'attribut est placé ailleurs.
Nous le mettons plutôt dans l'élément treeitem.
En fait, les éléments à l'extérieur (ou au-dessus) de l'élément qui a l'attribut
uri ne sont pas dupliqués tandis que les éléments avec
l'attribut uri et les éléments à l'intérieur sont répétés pour chaque ressource.
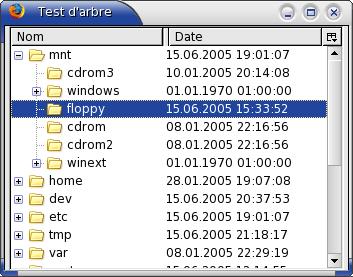 Comme un constructeur d'arbre est utilisé et non un constructeur de contenu, la structure
des éléments dans l'exemple ci-dessus doit être comme indiqué, avec l'élément
Comme un constructeur d'arbre est utilisé et non un constructeur de contenu, la structure
des éléments dans l'exemple ci-dessus doit être comme indiqué, avec l'élément
treechildren
à l'intérieur de rule.
Bien que le constructeur d'arbres ne génère pas ces éléments, cette structure est nécessaire
pour déterminer comment les générer correctement.
Notez dans l'image que des éléments fils additionnels ont été ajoutés automatiquement sous les éléments du niveau supérieur. XUL sait comment ajouter des éléments fils quand les modèles ou règles contiennent des éléments arbre ou menu. Il génère alors les éléments d'arbre imbriqués selon les données disponibles dans le RDF.
Une partie intéressante des sources de données RDF est que les valeurs sont déterminées seulement quand les données sont requises. Les valeurs qui sont plus profondes dans la hiérarchie de ressource ne sont pas déterminées jusqu'à ce que l'utilisateur atteigne ce noeud dans l'arbre. Ce mécanisme devient utile pour certaines sources où les données sont déterminées dynamiquement.
Si vous essayez l'exemple précédent, vous pouvez noter que la liste de dossiers n'est pas triée. Les arbres qui produisent leurs données à partir d'une source ont la capacité facultative de trier leurs données. Vous pouvez trier de façon croissante ou décroissante sur n'importe quelle colonne. L'utilisateur peut changer la colonne de tri et la direction de tri en cliquant sur les en-têtes de colonne. Ce dispositif de tri n'est pas disponible pour des arbres dont le contenu est statique, bien que vous puissiez écrire un script pour trier ces données.
Le tri implique trois attributs, qui doivent être placés sur les colonnes. Le premier attribut,
sort, doit être placé sur une propriété de RDF qui est employée alors
comme critère de tri. Habituellement, c'est la même que celle utilisée pour le libellé de la
cellule de cette colonne. Si vous le placez sur une colonne, les données seront triées dans cette
colonne. L'utilisateur peut changer la direction de tri en cliquant sur l'en-tête de colonne. Si vous
ne placez pas l'attribut sort sur une colonne, les données ne pourront
pas être triées par cette colonne.
L'attribut sortDirection (notez la casse mixte) est utilisé pour
définir la direction dans laquelle la colonne sera triée par défaut. Trois valeurs sont possibles :
Le dernier attribut, sortActive, doit être défini à true
sur une seule colonne, celle qui sera triée par défaut.
Bien que le tri fonctionnera correctement avec seulement ces attributs, vous pouvez également
utiliser la classe de style sortDirectionIndicator sur une colonne qui peut être triée.
Un petit triangle apparaîtra dans l'en-tête de colonne et indiquera le sens du tri.
Sans cela, l'utilisateur pourra toujours trier les colonnes mais il n'aura pas
d'indication sur la colonne triée.
L'exemple suivant modifie les colonnes de l'exemple précédent pour inclure les fonctionnalités supplémentaires :
<treecols>
<treecol id="Name" label="Name" flex="1" primary="true"
class="sortDirectionIndicator" sortActive="true"
sortDirection="ascending"
sort="rdf:http://home.netscape.com/NC-rdf#Name"/>
<splitter/>
<treecol id="Date" label="Date" flex="1" class="sortDirectionIndicator"
sort="rdf:http://home.netscape.com/WEB-rdf#LastModifiedDate"/>
</treecols>Une chose supplémentaire que vous voudrez faire est de rendre persistant la colonne
qui est actuellement triée, ainsi cet état est mémorisé entre chaque session.
Pour ce faire, nous utilisons l'attribut persist sur
chaque élément treecol.
Il peut être utile de rendre persistant cinq attributs : la taille de la colonne, l'ordre des
colonne, la visibilité de la colonne, quelle colonne est actuellement triée et dans quel ordre.
L'exemple suivant montre une simple colonne :
<treecol id="Date" label="Date" flex="1"
class="sortDirectionIndicator"
persist="width ordinal hidden sortActive sortDirection"
sort="rdf:http://home.netscape.com/WEB-rdf#LastModifiedDate"/>D'autres détails sur l'attribut persist seront décrits dans
une section ultérieure.
Deux attributs supplémentaires peuvent être ajoutés sur l'élément
rule, lui permettant
d'appliquer des correspondances dans certaines circonstances. Les deux sont des booléens.
iscontainerisemptyUne ressource pourrait être un conteneur et être vide en même temps. Toutefois, c'est différent pour une ressource qui n'est pas un conteneur. Par exemple, un dossier de marque-pages est un conteneur mait il peut avoir ou ne pas avoir d'enfants. Cependant, un simple marque-page ou un séparateur n'est pas un conteneur.
Vous pouvez combiner ces deux éléments avec d'autres attributs de critères pour des règles plus spécifiques.
Dans la section suivante, nous verrons quelques unes des sources de données fournies par Mozilla.
Mozilla® est une marque déposée de la fondation Mozilla.
Mozilla.org™, Firefox™, Thunderbird™, Mozilla Suite™ et XUL™
sont des marques de la fondation Mozilla.